電力現(xiàn)貨預(yù)測精度高不等于交易收益好:改造決策樹
枯藤老樹昏鴉,小橋流水人家。語文老師給我講這首詩的時候,說這個只是名詞的堆砌,但給人一種直指內(nèi)心的感覺。
——以上是這篇技術(shù)文章的核心思想。
(來源:微信公眾號“蘭木達(dá)電力現(xiàn)貨”作者:王超一)
一.兩種決策樹的差異對比
在講正題之前,先簡要講一下 scikit-learn(以下簡稱sklearn)決策樹的主要實現(xiàn)邏輯。另外,這一塊代碼位于 sklearn/tree 目錄下,而 ensemble 里的隨機森林依賴 tree 目錄代碼。
首先,構(gòu)造一棵決策樹有兩種邏輯,一種是深度優(yōu)先搜索DepthFirstTreeBuilder,即每次找到最優(yōu)的分裂節(jié)點,然后在左右子樹中按同樣邏輯構(gòu)建;另一種是類似寬度優(yōu)先搜索的貪心策略BestFirstTreeBuilder,之所以說是類似寬度優(yōu)先搜索,是因為每次都找到當(dāng)前的最優(yōu)分裂,而不是按層分裂,即把寬搜用的隊列換成優(yōu)先級隊列。用哪一種方式建樹取決于是否指定了最大葉子節(jié)點數(shù)T,如果指定了就用BestFirstTreeBuilder,因為這樣即使無腦搜索也是O(T2)復(fù)雜度,當(dāng)然sklearn用了基于堆的優(yōu)先級隊列可以將復(fù)雜度降低為O(TlogT)。
其次,除了構(gòu)建樹的方法外,剩下的邏輯核心在于 Splitter, Splitter也保存了原始的X、y、 sample_weight,Splitter主要有4個方法:
1)init 方法,保存原始X、y、sample_weight,生成一個對樣本(行)的索引表,并利用X和行索引表和一個特征的緩存數(shù)組生成一個Partitioner 對象;
2)node_reset方法,利用 y,sample weight和行索引構(gòu)造 Criterion 對象,分類樹的熵、基尼系數(shù),回歸樹的MSE,MAE都是在這個Criterion的實現(xiàn);
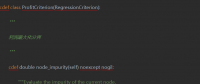
3)node_impurity方法,調(diào)用self.criterion.node_impurity計算一個節(jié)點的純度,這個數(shù)越小越好;
4)node_split 方法,本方法是核心,有兩個更基礎(chǔ)的方法,分別為 node_split_best 和 node_split_random,這兩個方法都調(diào)用了 Splitter、Partitioner、Criterion 3個對象,同時有很多性能上的優(yōu)化,如在行索引上操作,對快速排序的優(yōu)化,對常量特征的優(yōu)化等。
上邊這一段看不懂沒有關(guān)系,大致就是說,sklearn用cython寫了個樹的構(gòu)建,并把api暴露給python,然后每個關(guān)鍵點都有幾種選擇,這些一般都傳入字符串參數(shù),然后sklearn有內(nèi)置的字典來找到對應(yīng)的類,這些類用 Cython 實現(xiàn)來確保效率。
二.電力市場交易的優(yōu)化目標(biāo)是收益而不是偏差
問題在于,拿電力交易為例,我們最終的目標(biāo)是收益最大化,一般來說這個收益取決于當(dāng)前價格和未來價格之差,后文簡稱價差,如果我們構(gòu)造一個回歸樹,y為價差,那么可以選擇 MAE、MSE或其變種作為一個純度的度量,這樣就是把收益最大化問題轉(zhuǎn)換為價差的回歸了。這個數(shù)學(xué)建模的問題在于,雖然邏輯上更優(yōu)的價差預(yù)測會帶來更好的策略收益,但實踐中也不絕對,有可能把MAE降低了,策略收益沒有提高反而降低了。
能否給出一個直面目標(biāo)函數(shù)(策略收益)的決策樹呢?
首先,回過頭再看一下決策樹為我們提供了什么,決策樹給出了一些條件下的樣本集合,這些條件是分層的,可以定義這個樣本集合的一個指標(biāo),代表這個分層好不好,即決策樹是否恰當(dāng)劃分。那么這個指標(biāo)就可以直接定義為這個集合下按照某種交易策略下的利潤。
比如,我們有一種策略,只看預(yù)測價差的符號,不論價差大小,都申報同樣多的電量,那么這個集合的利潤就是所有價差之和的絕對值。
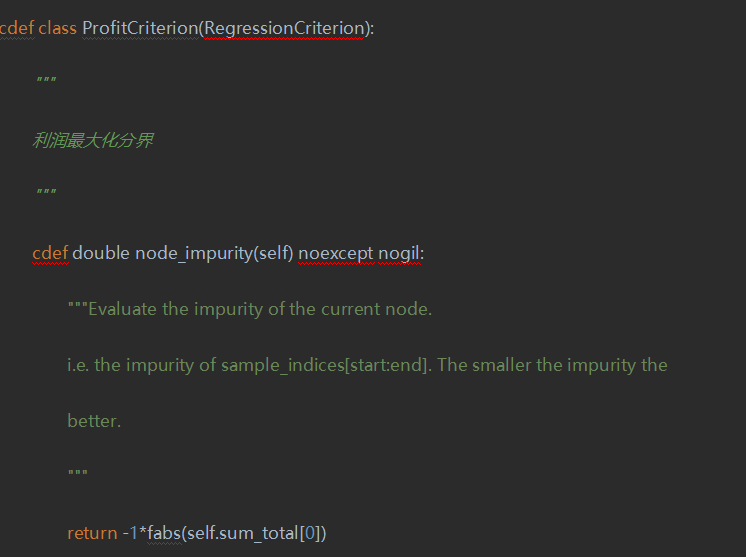
其次,還得重新實現(xiàn)proxy_impurity_improvement和children_impurity這兩個方法,限于篇幅原因不再贅述。這里面有個坑,這個純度即node_impurity 越小越好,那么我們利潤最大化得乘以-1,然而在sklearn中,默認(rèn)純度為正數(shù),我們開頭講的樹構(gòu)建過程中,如果純度小于一個極小正數(shù)時認(rèn)為當(dāng)前節(jié)點已經(jīng)是葉子節(jié)點了,所以得改樹構(gòu)建的邏輯,具體而言就是加上3個#注釋掉3行即可。
經(jīng)過這樣的改造,在山東日前交易中,回測利潤是MSE的3倍或更多。
接下來,我們更進(jìn)一步,注意到我們這里要用-1倍的利潤作為節(jié)點純度,對新能源電站,計算利潤需要更多的數(shù)據(jù),比如裝機容量、實際發(fā)電和預(yù)測發(fā)電,而實際發(fā)電在sklearn框架中是一個尷尬的存在。
我們不能把這個數(shù)值當(dāng)做X,因為這個是個未來數(shù)據(jù)。然而在回歸中,如果把這個數(shù)當(dāng)做y,在代碼邏輯上勉強能跑通,但會在代碼中把真正的y與輔助性的數(shù)據(jù)混在一起,代碼結(jié)構(gòu)化變差,比如在predict會得到一個二維矩陣。所以我們嘗試了修改 sklearn 的 api,分別給 BaseDecisionTree.fit、TreeBuilder.build、Splitter.init, Criterion.init 中增加相同的輔助計算節(jié)點純度的參數(shù),加上這個機制,就可以任意修改(節(jié)點純度)目標(biāo)函數(shù)了。
自定義的目標(biāo)函數(shù)讓我們可以直面交易利潤,把價差預(yù)測的學(xué)習(xí)直接升級到交易策略的學(xué)習(xí),然而,這也給我們提出了更高的決策樹后處理要求,對策略的過擬合也得有更多的控制手段。
最后吐槽一下,Pycharm 對 Cython 的支持太差了,右邊一堆紅(提示代碼錯誤),代碼折疊也有問題,可能逼著我們?nèi)ビ?vs code 了。
官方微信售電那點事兒")
責(zé)任編輯:葉雨田